Why institutional crypto teams cannot afford to ignore reference data
Crypto reference data: the invisible layer that makes or breaks your calculations
Date
Author
Gautier Humbert, Research Analyst

Introduction
When people talk about data in crypto finance, the conversation almost always centers on market data: prices, volumes, order books. Reference data stays in the background. And yet it determines the validity of everything else.
Without reliable reference data, a price is just a number without context. You do not know which asset it belongs to, on which market it was quoted, or whether the instrument still exists. For a crypto fund, an asset manager, or a quantitative team, that ambiguity is not a minor inconvenience, it is a direct source of errors in NAV calculations, P&L attribution, and exposure reporting.
Institutional players in traditional financial markets have benefited for decades from a robust, standardized reference infrastructure. In the crypto world, standards are emerging: the DTI (ISO 24165), made mandatory under MiCA for issuers and CASPs, is an important regulatory step. But it covers only part of the problem. The operational layer, exchange symbol mapping, market coverage, collision detection, primary market identification, remains largely unaddressed. Building that layer, maintaining it, and making it reliable at an institutional level is precisely what Koinju does, with today more than 4,500 unique assets, 20,000 markets, and 13,500 intermediaries covered across spot and derivatives markets.
What Traditional Finance Takes for Granted
In traditional financial markets, every instrument has a standardized, universal identifier. The ISIN uniquely identifies a security anywhere in the world. The LEI identifies a legal entity. The FIGI identifies a specific market instrument. These standards are maintained by central bodies (ISO, GLEIF, ANNA) whose sole purpose is to guarantee the uniqueness and stability of these identifiers over time.
In practice, this means that a bond issued in Paris and traded in Tokyo shares the same ISIN on both markets. A fund manager in London and a depositary in Luxembourg are talking about the same instrument when they use the same identifier. A reporting system can aggregate data from dozens of different counterparties and custodians with full confidence that the identifiers are consistent. A risk system can calculate net exposure across brokers without fear of counting the same security twice under different names.
This guarantee is so fundamental that it is invisible. It is one of the baseline conditions on which the entire institutional finance infrastructure rests from trade execution to settlement confirmation, from NAV calculation to regulatory reporting. When a corporate action modifies an instrument, the reference data update follows a formalized process: announced, timestamped, propagated through established channels, with a full audit trail. Teams working in traditional finance have internalized all of this to the point of no longer thinking about it.
The crypto market has begun to address this, but only at the regulatory level of token identification. The operational layer remains to be built. And that is where the problem begins.
The Symbol Fragmentation Problem
In the crypto ecosystem, there is no central identifier authority at the exchange level. The DTI (ISO 24165) identifies tokens technically: contract address, DLT network but says nothing about how those tokens are listed on markets: under which symbols, on which platforms, with what liquidity. Each exchange freely chooses its own symbols, without coordination with other platforms. The result is a tower of Babel where the same asset can have a different name depending on which platform it trades on.
Bitcoin is the most well-known example: quoted as BTC on Binance and Coinbase, but as XBT or XXBT on Kraken. This is not an error on Kraken's part, it is a convention inherited from the ISO 4217 currency notation standard. But for a system aggregating multi-exchange data without reconciliation, these three symbols appear as three distinct assets. Net exposure is miscalculated. NAV is wrong.
This is precisely the type of problem that ISIN was designed to eliminate in traditional markets. A portfolio management system aggregating equity positions across multiple prime brokers does not need to reconcile naming conventions, the ISIN handles that by construction. Without an equivalent in the crypto world, every team must solve it themselves or ignore it, at the risk of silent errors compounding in their calculations.
The problem compounds as you move down the market cap spectrum, where naming conventions are even less standardized. For an institutional team managing positions across multiple exchanges simultaneously, manually reconciling these divergences is a source of significant operational costs and error risk, time spent on a problem that simply does not exist in traditional finance.
The Symbol Collision Problem
More dangerous still: two different assets can share the same symbol across two different exchanges. In traditional finance, this scenario is impossible by construction, the ISIN is unique, full stop. In the crypto world, it is common.
The symbol AI refers to Gensyn on some platforms, and Sleepless AI on others. These two tokens have nothing in common, not the team, not the use case, not the market cap. A system that matches symbols without cross-validation will treat them as a single asset — generating valuations based on the wrong token. The symbol ALT can refer to an altcoin index on certain derivatives exchanges, and to the Altlayer token on others. One is a synthetic derivative product, the other a native token. Conflating them in a portfolio report is the equivalent of treating a futures contract and its underlying equity as the same instrument.
These collisions are the natural product of a market without centralized identifier governance, where thousands of new tokens are created every year. For institutional actors subject to precise reporting obligations (AIFMD, fund audit…), this level of ambiguity is simply unacceptable. A traditional finance team would never accept a reference data system that could confuse two different securities. There is no reason to accept it for crypto.
Querying the Wrong Data Without Knowing It
The most insidious consequence of these problems is that the error is silent.
When you query a crypto data API with the symbol AI, you get a response. No HTTP error, no warning. The API returns prices, volumes, historical series and everything appears to work. An entire pipeline can be built on the basis of the wrong asset without ever receiving a single alert. Unlike a failed database query, there is no stack trace to investigate and no alert to trigger an incident response.
For a fund, this can mean a NAV calculated using Sleepless AI prices when Gensyn was intended. For a quant team, backtests that are statistically valid but economically meaningless. These errors do not surface in logs, they surface in audits, or during the manual reconciliations that follow unexplained discrepancies.
There is a subtler but equally consequential dimension to this problem: fair value calculation. For any asset traded across multiple exchanges, determining a fair value requires first identifying which market is the primary one, the market with the deepest liquidity and the most representative price. In traditional finance, this is a solved problem: the primary listing of a security is part of its reference data, and pricing sources are selected accordingly. In crypto, without a reliable registry that maps each asset across all its exchange representations, there is no systematic way to identify the primary market. A fund that prices a mid-cap token using a thin, low-liquidity exchange, simply because it was the first match returned by a symbol lookup, is not calculating a fair value. It is calculating a noise-prone proxy that may diverge significantly from the true market price. For NAV calculations, this is not a theoretical risk. It is a valuation methodology issue that auditors and depositaries will flag.
Our Response: Canonical Identifiers and Active Supervision
koinju_asset_symbol and koinju_asset_id
In the absence of operational identification standards in the crypto ecosystem, Koinju has built its own canonical identifier system designed to fill precisely the gap left by the absence of an ISIN equivalent in the crypto world.
The koinju_asset_symbol is a human-readable symbol, defined independently of each exchange's conventions, with one absolute constraint: no collision is possible. Two distinct assets can never share the same koinju_asset_symbol. We always try to keep the most common symbol of the asset among all exchanges.
The koinju_asset_id is a randomly generated string assigned once and for all to each asset. Its random nature is deliberate: it encodes no information that could become obsolete and depends on no naming convention. It plays in our registry the role that ISIN plays in traditional financial markets — a permanent identifier that survives rebranding, symbol migrations, and exchange nomenclature changes. For institutional systems that need a stable join key over the long term, historical databases, reconciliation engines, regulatory archives, the koinju_asset_id is the primary reference.
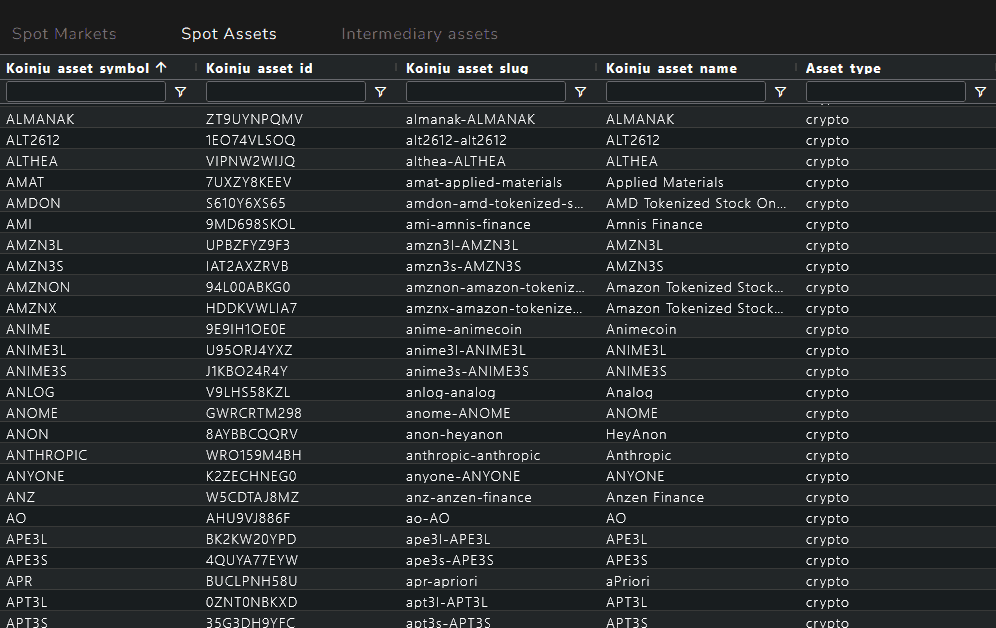
The Intermediaries System
The link between exchange symbols and the koinju_asset_symbol is handled by the intermediaries table: the mapping layer that connects each exchange representation to its Koinju canonical identifier. For Bitcoin, it links BTC on Binance, XBT and XXBT on Kraken to a single asset, in the same way that an ISIN registry reconciles the different representations of the same security across multiple markets and custodians. It is the reconciliation layer that traditional finance has always had and that the crypto ecosystem has been missing.
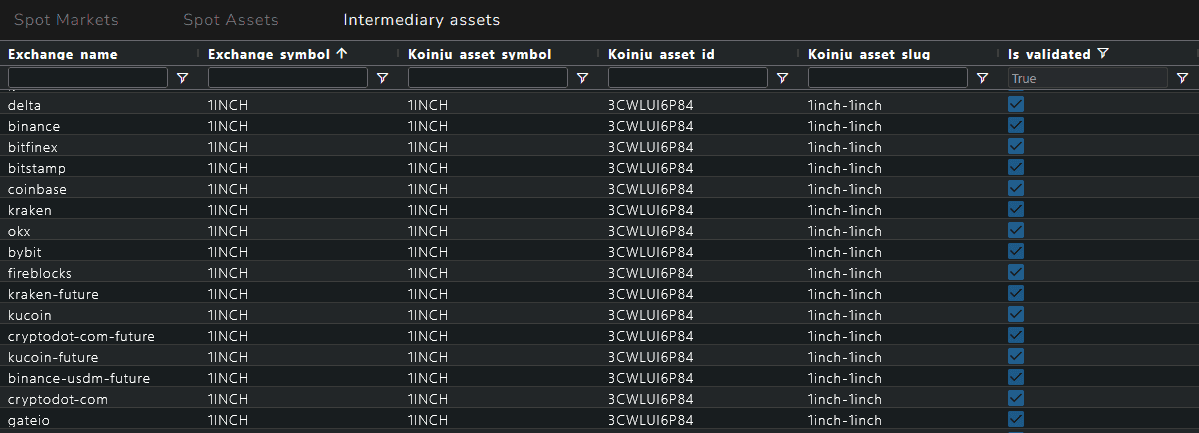
Human Validation at Every Step
Our registry is fed directly from exchange APIs, cross-referenced with official exchange announcements and third-party reference sources. No entry is validated automatically: a human reviews and validates every instrument before it enters the database, assisted by AI tools that accelerate the detection of anomalies and ambiguous cases. This mirrors the data governance model of traditional finance institutions, where no reference data enters production without passing a formalized quality control, and is what allows us to provide an institutional-grade guarantee on every entry in our registry.
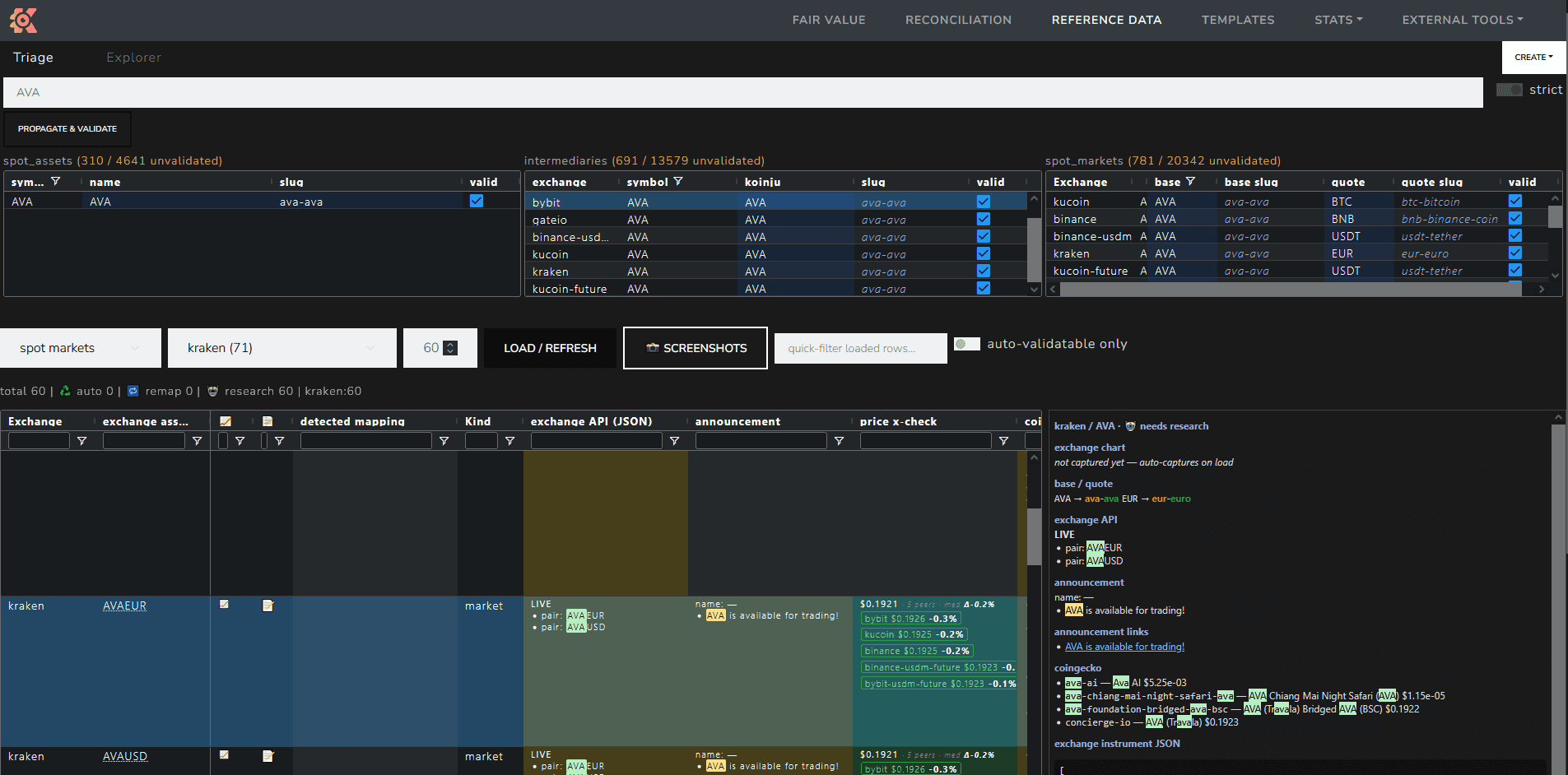
Illustrated above is our validation control screen. It will soon be available in the client portal.
What This Changes in Practice
For a fund manager or asset manager, institutional-grade reference data means NAV and performance reports without manual rework, and the ability to produce regulatory compliance statements, AIFMD, MiCA, depositary reporting, with a full audit trail on every instrument. The same guarantees they have always relied on for their traditional portfolios, now applied to their crypto positions.
For a quantitative team, models that rely on stable, reconciled identifiers rather than raw exchange symbols, eliminating silent errors during multi-exchange aggregation and guaranteeing the consistency of historical series.
For a fintech building products for institutional clients, a reference data layer that meets their clients' requirements without having to build and maintain that infrastructure in-house.
Access the Reference Data via API
Koinju's reference data is accessible directly via API. Teams can query the full registry: assets, markets, and intermediaries, filter by exchange, and integrate the data directly into their pipelines, pricing engines, or reporting systems. The API is built for production use and designed for the integration requirements of institutional teams.
If you would like to access our reference data or learn more about our API, get in touch.
Documentation: Here